
字符串编码
由于历史原因, 字符在内存中的编码都是Unicode, 但是对于一些数字或英文字符, 那么用Unicode就会严重浪费空间和带宽,所以在硬盘上或网络传输上的字符编码大多都是utf-8的.
Str
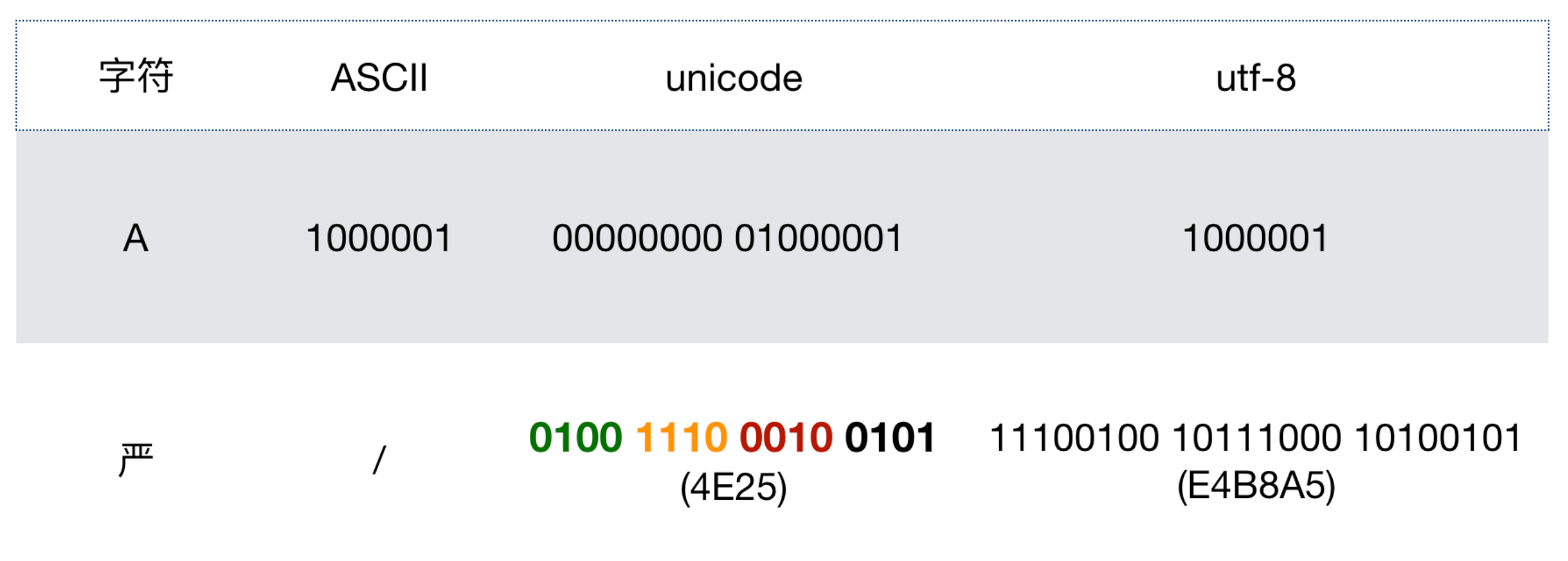
汉字‘严’在python中的字符表示有两种
>>> '严'
'严'
>>> '\u4e25'
'严'可以用ord()查看字符的整数表示.
>>> ord('严')
2000520005的16进制数就是4E25, 正是\u4E25.
可以用chr()将整数转换为相应的字符
>>> chr(20005)
'严'
>>> int('4e25', 16)
20005Bytes
>>> type(b'ABC')
<class 'bytes'>
>>> type('ABC')
<class 'str'>
>>>使用b''方式来表达一个bytes, 虽然显示出来是一样的,但内部存储方式是不同的.
以Unicode表示的str通过encode('utf-8')转为bytes:
>>> '严'.encode('utf-8')
b'\xe4\xb8\xa5'从硬盘等其他地方获取的bytes用decode('utf-8')转换为str:
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'长度
>>> len('abc')
3
>>> len('中文')
2
>>> len('严')
1
>>> len(b'abc')
3
>>> len('严'.encode('utf-8'))
3len()函数对于str计算的是字符数,对于bytes计算的是字节数.
1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节.
ps. 之前计算过严->4E25->E4B8A53个字节存储.




