在上一篇文章中,简单介绍了 LLM 的训练流程和 Transformer 的自注意力机制。这篇文章想把 Transformer 的内部结构拆得更细一些——从分词到 Embedding,从 QKV 到因果掩码,从 FFN 到残差连接,再到推理阶段的 Prefill 与 Decode。
分词:BPE
在进入模型之前,文本需要先被切成 token。现代 LLM 普遍使用 BPE(Byte Pair Encoding)分词算法。BPE 的核心思路是:从字符级开始,不断合并出现频率最高的相邻字符对,直到达到预设的词表大小。
"unhappiness"↓ BPE 分词["un", "happi", "ness"] # 3 个 token
"ChatGPT"↓ BPE 分词["Chat", "G", "PT"] # 3 个 tokenBPE 的好处:
- 词表可控(通常 32K-100K)
- 永远不会 OOV(最差情况拆成单字符)
- 能捕捉词根词缀的语义(
un-表否定,-ness表名词化)
分词之后,每个 token 会被映射为一个整数 ID(token ID),这是模型唯一认识的东西。
Embedding:离散到连续
拿到 token ID 之后,需要通过 Embedding Matrix 把离散的整数映射为连续的高维向量。Embedding Matrix 本质上就是一个查找表:
假设词表大小 V = 128,000,embedding 维度 d = 4096那么 Embedding Matrix 的 shape 就是 (128000, 4096)
Token ID = 2054 → 取矩阵第 2054 行 → 得到一个 4096 维向量每个向量就是一个浮点数数组:
[0.0234, -0.1892, 0.4521, ..., 0.0087] # 4096 个数这些数字是训练出来的,不是人工设定的。训练之后,语义相近的词在高维空间中的向量距离会更近,比如君主和帝王两个会距离会近些。
具体来说,一个句子经过分词和 Embedding 后的变换过程:
token_ids = [101, 2054, 2024, 2027, ...] # 长度 11 ↓embedding_matrix[token_ids] ↓[embedding_matrix[101], embedding_matrix[2054], embedding_matrix[2024], ...] ↓shape: [11, 4096] 即 [seq_len, hidden_size]每个 token 对应一个 4096 维向量。整个序列就变成了一个 (seq_len, hidden_size) 的矩阵(张量),交给后续的 Transformer 层处理。
顺带说一下维度术语:
| 维度 | 数学术语 | 代码里常叫 |
|---|---|---|
| 0维 | 标量 | scalar |
| 1维 | 向量 | vector / 1D array |
| 2维 | 矩阵 | matrix / 2D array |
| 3维+ | 张量 | tensor / ND array |
Embedding Matrix 是 2D 矩阵,但 Transformer 里流动的数据通常是 3D 张量(加了 batch 维度)。
数学基础:矩阵乘法、点积与加权求和
在进入 Attention 之前,先理清几个反复出现的数学操作——它们是理解 Transformer 的基石。
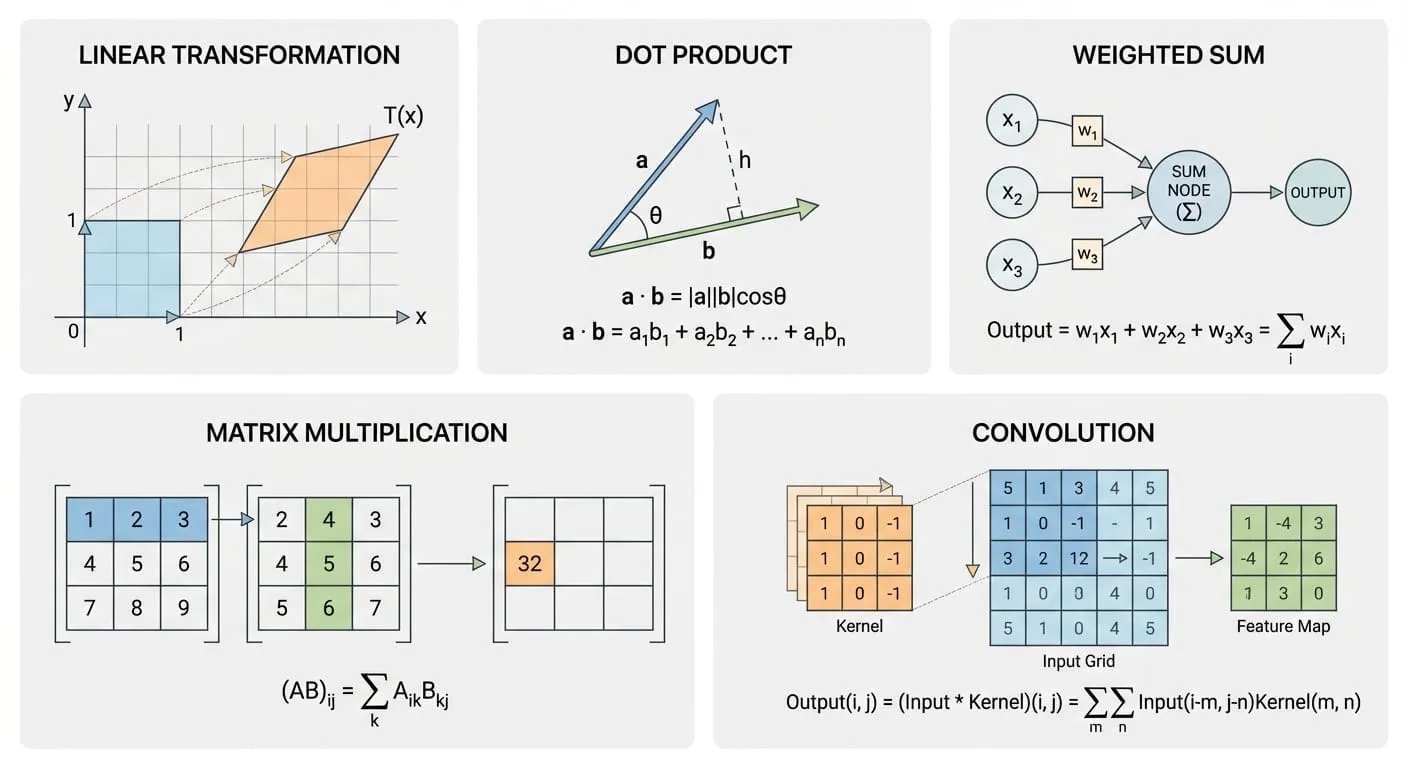
点积(Dot Product / 内积):两个向量逐元素相乘再求和,得到一个标量。几何上就是「一个向量在另一个上的投影长度 × 另一个的长度」,可以衡量两个向量的相似度:
$$a \cdot b = a_1b_1 + a_2b_2 + \cdots + a_nb_n = |a||b|\cos\theta$$
加权求和(Weighted Sum):给每个输入一个权重,乘完之后加起来。神经网络的基础操作——每个神经元做的就是加权求和再过激活函数:
$$\text{Output} = w_1x_1 + w_2x_2 + w_3x_3 = \sum_i w_i x_i$$
矩阵乘法(Matrix Multiplication):本质就是「批量做点积」。矩阵 A 的每一行和矩阵 B 的每一列做点积,得到结果矩阵的对应位置:
在 Transformer 里,这三个操作无处不在:
Q @ K^T就是批量点积——算每对 token 的相似度softmax(scores) @ V就是加权求和——按相似度把 V 混合X @ W就是矩阵乘法——线性变换把向量映射到新空间
它们本质上是同一个操作在不同维度上的表现。理解了这一点,后面的 Attention 公式就不再神秘了。
Attention:信息融合
拿到 Embedding 向量之后,进入 Transformer 的核心——自注意力机制。
QKV 变换
每个 token 的向量 X 通过三个不同的权重矩阵进行线性变换(矩阵乘法),得到 Query、Key、Value:
Q = X @ Wq # (n, 4096) @ (4096, 4096) → (n, 4096)K = X @ Wk # 同上V = X @ Wv # 同上实际在 PyTorch 等框架中,为了效率通常是将 Wq、Wk、Wv 拼成一个大矩阵 W_qkv
(4096, 4096×3),一次矩阵乘法X @ W_qkv算完再拆分成 Q、K、V,效果等价但更快。
直观理解:
- Q(Query):“我该关注谁?”
- K(Key):“我是什么,匹不匹配?”
- V(Value):“如果匹配了,拿走我的信息。“
注意力计算
$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V$$
分步拆解,假设序列长度 n=4:
Step 1:计算注意力分数
scores = Q @ K^T # (4, 4096) @ (4096, 4) → (4, 4)这里的各个符号:
- Q(Query 矩阵):shape 是
(n, d_k),即(4, 4096)。每一行是一个 token 的查询向量,代表「我在找什么」 - K^T:K 的转置(Transpose)。K 原本是
(n, d_k)即(4, 4096),转置后变成(d_k, n)即(4096, 4)。转置是为了让 Q 的每一行能和 K 的每一行做点积——矩阵乘法要求「前者的列数 = 后者的行数」 - d_k(dimension of Key):Key 向量的维度。在单头注意力中就是 hidden_size(如 4096);在多头注意力中是
hidden_size / num_heads(如 4096/32 = 128)
Q @ K^T 得到一个 n×n 的矩阵,本质是批量做点积——Q 的第 i 行和 K 的第 j 行做点积,得到 token i 对 token j 的关注程度。除以 √d_k 是为了防止点积值过大导致 softmax 梯度消失(维度越高,点积值越大,除以 √d_k 做缩放)。
Step 2:softmax 归一化
对分数矩阵的每一行做 softmax,让每行的权重和为 1:
x1 x2 x3 x4x1 [ 0.8 0.1 0.05 0.05 ] ← x1 主要关注自己x2 [ 0.2 0.5 0.2 0.1 ] ← x2 关注自己和 x1x3 [ 0.1 0.3 0.4 0.2 ]x4 [ 0.05 0.15 0.3 0.5 ]softmax 是一个非线性归一化函数,它把任意实数向量压缩成概率分布(所有值为正数,且和为 1)。
Step 3:加权求和
output = scores @ V # (4, 4) @ (4, 4096) → (4, 4096)每个 token 的输出向量 = 所有 token 的 V 向量的加权平均,权重就是注意力分数。这又回到了原始输入的形状,每一行现在包含了该 token 结合了上下文信息后的新表示。
所以 Attention 的输出不是一个标量,而是和输入同 shape 的向量序列——每个向量都「看过」了其他位置,融合了上下文信息。
| 中间产物 | Shape | 含义 |
|---|---|---|
| Q, K, V | (n, d) | 每个 token 的查询/键/值向量 |
| Q @ K^T | (n, n) | 注意力分数矩阵 |
| softmax(…) | (n, n) | 归一化后的注意力权重 |
| 最终输出 | (n, d) | 融合上下文后的新向量序列 |
实际的 Transformer 使用的是 Multi-Head Attention:将 Q、K、V 拆分到多个 head(比如 32 个),每个 head 独立计算注意力,最后 concat 起来。concat 之后还需要经过一个 Output Projection(W_o 矩阵)线性变换,才能变回 (n, d) 与残差相加。这样不同的 head 可以关注不同维度的特征,W_o 则负责将多头的信息融合映射回原始维度。
因果掩码(Causal Mask)
GPT、Claude、Llama 这些生成式模型都是 Decoder-only 架构,使用单向自回归——当前 token 只能看到自己和之前的 token,不能偷看后面的:
"青岛 啤酒"
处理「青岛」时:只能看到自己(和之前的词)处理「啤酒」时:可以看到「青岛」+ 自己这就是因果掩码——把未来信息遮住。实现方式是在 attention score 矩阵上应用一个上三角 mask,把不该看的位置设为 -∞,这样经过 softmax 后权重变成 0。
掩码如何工作?
以 3 个 token 为例。先做完整的矩阵乘法 Q @ K^T,得到 3×3 的注意力分数矩阵,然后把上三角部分替换为 -∞:
词1 词2 词3Score = 词1 [ 词1对1 -∞ -∞ ] 词2 [ 词2对1 词2对2 -∞ ] 词3 [ 词3对1 词3对2 词3对3 ]当对每一行做 softmax 时,e^(-∞) 趋近于 0,这些位置的权重就被「消灭」了:
softmax 后: 词1 [ 1.0 0 0 ] ← 词1 只能看到自己 词2 [ 0.4 0.6 0 ] ← 词2 只能看到 1 和 2 词3 [ 0.2 0.3 0.5 ] ← 词3 能看到 1, 2, 3物理上,我们只做了一次全量的矩阵乘法 Q @ K^T——所有 token 的注意力分数同时算出来。但通过这个「下三角」掩码,逻辑上实现了「每个 token 只能看到它之前的内容」的效果。
注:具体在模型推理阶段(Prefill),掩码机制是如何让所有 token 实现一次性并行计算的,我们会在后文的「推理流程」部分详细解释。
完整示例:从 QKV 到输出
用一个中文句子把上面的步骤串起来。输入「我 爱 青岛 啤酒」(n=4,d=3):
Step 1:生成 Q, K, V
Q = [[q1], [q2], [q3], [q4]] # 每个 token 的「问题」K = [[k1], [k2], [k3], [k4]] # 每个 token 的「标签」V = [[v1], [v2], [v3], [v4]] # 每个 token 的「内容」Step 2:Q · K^T → 原始相似度矩阵(4×4)
我 爱 青岛 啤酒我 [0.8 0.5 0.3 0.2 ]爱 [0.3 0.4 0.6 0.1 ]青岛 [0.1 0.2 0.5 0.4 ]啤酒 [0.1 0.1 0.3 0.5 ]Step 2.5:应用因果掩码(上三角 → -∞)
我 爱 青岛 啤酒我 [0.8 -∞ -∞ -∞ ]爱 [0.3 0.4 -∞ -∞ ]青岛 [0.1 0.2 0.5 -∞ ]啤酒 [0.1 0.1 0.3 0.5 ]Step 3:softmax(-∞ → 0)
我 爱 青岛 啤酒我 [1.0 0 0 0 ]爱 [0.4 0.6 0 0 ]青岛 [0.2 0.3 0.5 0 ]啤酒 [0.1 0.1 0.3 0.5 ]Step 4:权重 · V → 加权混合
output = attention_weights @ V # (4, 4) @ (4, 4096) → (4, 4096)用具体数字来看这个矩阵乘法的过程。注意力权重矩阵(经过因果掩码 + softmax 后):
我 爱 青岛 啤酒我 [1.0 0 0 0 ]爱 [0.4 0.6 0 0 ]青岛 [0.2 0.3 0.5 0 ]啤酒 [0.1 0.1 0.3 0.5 ]V 矩阵(每个 token 的 Value 向量,每行 4096 维):
V = [ [0.1, 2.0, 1.0, ...] ← v我,4096 个数 [0.2, 1.0, 2.0, ...] ← v爱,4096 个数 [0.3, 2.0, 1.0, ...] ← v青岛,4096 个数 [0.4, 1.0, 2.0, ...] ← v啤酒,4096 个数 ]矩阵乘法的本质就是:输出的每一行 = 注意力权重对 V 的每一列做加权求和。逐行来看:
- 「我」(第 1 行):权重是
[1.0, 0, 0, 0]——只有自己的权重非零,所以 4096 维中每一维都只是1.0 × v我。结果就是 v我 本身,没有融合任何其他信息 - 「爱」(第 2 行):权重是
[0.4, 0.6, 0, 0]——对 4096 维中每一维做0.4 × v我 + 0.6 × v爱。融合了「我」和「爱」两个 token 的信息 - 「青岛」(第 3 行):权重是
[0.2, 0.3, 0.5, 0]——对每一维做0.2 × v我 + 0.3 × v爱 + 0.5 × v青岛。融合了前三个 token 的信息 - 「啤酒」(第 4 行):权重是
[0.1, 0.1, 0.3, 0.5]——对每一维做0.1 × v我 + 0.1 × v爱 + 0.3 × v青岛 + 0.5 × v啤酒。融合了所有 token 的信息
可以看到,因为因果掩码让上三角为 0,每个 token 只能加权求和它自己和之前的 V 向量。越靠后的 token,能「看到」的信息越多,输出向量融合的上下文也越丰富。
另外注意「啤酒」的输出中,「青岛」贡献了最大的外部权重(0.3),这正符合直觉——「青岛」和「啤酒」语义关联最强。
这也意味着对于「青岛 啤酒」和「青岛 航空」,GPT 在处理「青岛」时并不知道后面是「啤酒」还是「航空」。它的理解是通过层层堆叠实现的——后续 token 融合了「青岛」的信息,最终模型基于整体语境生成输出。
FFN:知识存储
Attention 之后,每个位置的向量还要过一个 FFN(Feed-Forward Network,前馈网络):
FFN(x) = Linear2(activation(Linear1(x)))
具体:x: (4096,) ↓ Linear1: (4096 → 11008) # 先扩大约 2.7 倍 ↓ 激活函数 ↓ Linear2: (11008 → 4096) # 再压回来输出: (4096,)Attention 只做「信息混合」——让 token 之间交流,但矩阵乘法本身是线性的。FFN 引入了非线性变换,让模型能学到更复杂的特征:
- Attention = 「谁和谁相关」
- FFN = 「学到了相关性之后,怎么处理这个信息」
有研究认为 FFN 是模型存储「知识」的地方(比如「巴黎是法国首都」这类事实)。
一个重要的事实:大约 2/3 的参数在 FFN 里,FFN 才是参数大户,Attention 层的参数相比之下反而少一些。
线性变换与非线性变换
在进入激活函数之前,先理解「线性」和「非线性」的核心区别。
线性变换(如矩阵乘法 X @ W):不管输入是什么,整个空间被「统一规则」对待——拉伸、旋转、投影。直线变换之后仍然是直线,平行线永远平行,原点不动。就像把一张橡皮纸均匀地拉伸和旋转,纸上的网格线永远保持笔直。
非线性变换(如 ReLU、softmax):空间的不同区域用不同规则对待。比如 ReLU 把负值压成 0、正值原样放行——这就像在 x=0 处折了一刀,直线被截断、弯折。每个区域的行为不一样,空间被局部扭曲。
线性变换: f(x) = 2x → 输入 [-3, -1, 0, 1, 3] → [-6, -2, 0, 2, 6](全局等比拉伸)非线性变换: f(x) = max(0,x) → 输入 [-3, -1, 0, 1, 3] → [ 0, 0, 0, 1, 3](负值被截断)为什么这很重要?纯线性变换无论堆多少层,都等于一层:
Linear2(Linear1(x)) = (W2 @ W1) @ x = W_combined @ x还是线性的!没有非线性,神经网络就是一个大矩阵乘法,无法学到复杂的模式。所以 FFN 里必须引入非线性的激活函数。
激活函数:ReLU 与 SwiGLU
ReLU 是最经典的激活函数:
ReLU(x) = max(0, x)# 负数变 0,正数不变但现代 LLM(如 Llama、Gemma)普遍使用 SwiGLU 替代 ReLU。SwiGLU 更平滑,训练效果更好。
LayerNorm:归一化
LayerNorm(层归一化)的作用是把向量「洗」一遍——让均值变为 0,方差变为 1:
def LayerNorm(x): mean = x.mean() std = x.std() return (x - mean) / std * gamma + beta # gamma, beta 是可学习参数深层网络训练时,每层的输出数值分布会漂移。LayerNorm 让每层输入保持稳定,训练更快更稳。可以类比考试分数标准化:原始分 80 分不知道好不好,标准化后 z=1.5 表示前 7%。
注意 LayerNorm 和 softmax 的区别:
- softmax:非线性归一化,把向量压缩成概率分布(所有值为正,和为 1)
- LayerNorm:把向量标准化到均值 0、方差 1,值可以是负数,和不一定为 1
残差连接
残差连接的核心思想:输出 = 输入 + 变换(输入)
output = x + Attention(x) # 而不是 output = Attention(x)为什么需要残差连接?
- 梯度流动:几十层的深层网络反向传播时,梯度容易消失或爆炸。有了残差,梯度可以「抄近道」直接流回浅层
- 学习增量:网络只需要学「在原来基础上改多少」,比从零学整个映射更容易
- 保底机制:最差情况,Attention 输出为 0,结果还是原来的 x,不会更差
残差 + LayerNorm 实际数据流
用一个具体的数字例子来看残差连接 + LayerNorm 如何协同工作,以及为什么它们能让 80 层的深层网络稳定训练:
第1层输入 x: [-0.3, 1.2, -0.8, ..., 0.5]第1层输出 F(x): [ 0.2, -0.1, 0.4, ..., -0.3] ← 这一层学到的「增量」
加残差 x + F(x): [-0.1, 1.1, -0.4, ..., 0.2] ← 基本保持了原始幅度再 LayerNorm: [-0.4, 1.3, -0.7, ..., 0.6] ← 标准化到均值≈0,方差≈1
... 重复 30 层 ...
第30层输入:仍然是幅度在 [-几, +几] 的合理向量,不会崩掉 ✓如果没有残差和 LayerNorm 会怎样? 每层的输出可能越来越大(爆炸)或越来越小(消失),到第 30 层时数值已经变成天文数字或接近零,根本无法使用。
梯度直通(Gradient Highway):反向传播时,梯度需要从第 80 层一路传回第 1 层。残差连接的 x + F(x) 对 x 求导时,导数里有一个恒定的 1(来自直通路径),不管 F(x) 的梯度有多小,至少保证有 1 的梯度能流回去。这就像在高速公路旁修了一条直通车道——即使主路堵了,梯度也能走辅路到达前面的层,确保浅层参数能持续更新。
完整的单层 Transformer
把上面所有组件拼起来,一个完整的 Transformer 层(Pre-Norm 结构,GPT/Llama 常用):
输入 x ↓x1 = LayerNorm(x) ← 归一化 ↓x2 = x + MultiHeadAttention(x1) ← Attention + 残差连接 ↓x3 = LayerNorm(x2) ← 归一化 ↓output = x2 + FFN(x3) ← FFN + 残差连接 ↓进入下一层| 组件 | 作用 |
|---|---|
| Attention | token 之间交流信息 |
| FFN | 处理/存储知识,引入非线性 |
| 激活函数 (SwiGLU) | 让网络能学非线性关系 |
| LayerNorm | 稳定训练,防止数值漂移 |
| 残差连接 | 让梯度流通,训练深层网络不退化 |
一个典型的 LLM(如 Llama 70B)会堆叠 80 层这样的结构。
LM Head:输出层
在生成任务中,经过多层(每一层都有独立的 Wq、Wk、Wv 权重矩阵)Transformer 计算之后,之前的输出(如 Z1~Z8)不再需要,我们只取最后一个位置的输出向量(如 Z9)。因为自回归模型的因果掩码保证了最后一个 token 已经融合了前面所有 token 的信息。我们需要把这个最终向量映射回词表,得到下一个 token 的概率分布,这一步通过 LM Head 完成:
logits = Z_last @ LM_Head # (4096,) @ (4096, 128000) → (128000,)probs = softmax(logits) # 归一化成概率next_token = sample(probs) # 根据概率采样LM Head 的 shape 是 (hidden_dim, vocab_size)。很多模型会使用 weight tying(权重绑定)——LM Head 就是 Embedding Matrix 的转置。这样做既节省参数,又保持了语义一致性:Embedding 时 token → 向量,输出时向量 → token,用的是同一个映射的正反方向。
推理流程:Prefill + Decode
LLM 的推理(inference)分为两个阶段:
Prefill 阶段
用户输入的所有 token 一次性全量计算:
用户输入: "请将你好翻译成英文"↓ 分词tokens: [token1, token2, ..., token9] # 9 个 token↓ EmbeddingX: [X1, X2, ..., X9] # 9 个向量↓ 进入 32 层 Transformer↓ 每层并行计算所有 token 的 Attention + FFN↓ 每层产出 [Z1, Z2, ..., Z9],作为下一层输入↓ 最后一层输出的 Z9 → LM Head → 下一个 tokenPrefill 是全量计算:Attention 矩阵是 n×n 的,每一层要等所有 Z 计算完才进入下一层。但同一层内所有 token 的计算是 GPU 并行的,所以 Prefill 虽然计算量大,但吞吐量高。
每一层还会缓存 K 和 V,存入 KV Cache 供后续 Decode 使用。
Decode 阶段
从 Prefill 算出第一个输出 token 之后,进入逐 token 生成:
已有: [X1, X2, ..., X9] → KV Cache 已就绪
生成第 10 个 token: 输入: 只有 X10(新 token 的 embedding)
Layer 1: Q10 = X10 @ Wq # 只算 1 个 Q K10 = X10 @ Wk → 追加到 KV Cache V10 = X10 @ Wv → 追加到 KV Cache
Attention: Q10 和 [K1...K10] 做点积 → 1×10 的注意力 加权 [V1...V10] → 得到 Z10
Layer 2~32: 同上,每层输入和输出都只有 1 个向量
最终: Z10 → LM Head → 第 11 个 tokenDecode 每次只跑一个 token 的 Attention(利用 KV Cache),不需要重新算之前所有 token 的 K、V。
对比
| Prefill | Decode | |
|---|---|---|
| 输入 | n 个 token(全部) | 1 个 token(新生成的) |
| 每层输出 | n 个向量 | 1 个向量 |
| Attention 矩阵 | n × n | 1 × n |
| 瓶颈 | 计算密集(compute-bound) | 内存带宽(memory-bound) |
| GPU 利用率 | 高(并行) | 低(串行) |
这就是为什么输入很长的 prompt 时,需要等几秒才开始输出(Prefill 在跑全量计算),而一旦开始输出,速度还行(Decode 每次只算 1 个 token)。
KV Cache
每一层都有独立的 KV Cache,因为每层的 Wk、Wv 权重矩阵不同,产生的 K、V 也完全不同:
kv_cache = { "layer_0": {"K": (n, num_heads, head_dim), "V": (n, num_heads, head_dim)}, "layer_1": {"K": ..., "V": ...}, ... "layer_31": {"K": ..., "V": ...},}KV Cache 是 Decode 阶段的加速关键——避免重复计算前面 token 的 K 和 V。但它也是显存消耗的大户:对于 100K 上下文长度的请求,KV Cache 可以轻松吃掉几十 GB 显存。
注意 KV Cache 只优化 Decode 阶段。Prefill 是第一次处理输入,没有缓存可用,必须全量计算。(除非使用 Prompt Caching 之类的技术,把常用 system prompt 的 KV 预先算好)
为什么长上下文 Prefill 很贵?
Attention 的核心 Q @ K^T 复杂度是 O(n²·d):
| 上下文长度 | Q @ K^T 矩阵大小 | 相对计算量 |
|---|---|---|
| 4K | 4K × 4K = 16M | 1x |
| 32K | 32K × 32K = 1B | 64x |
| 100K | 100K × 100K = 10B | 625x |
所以各家都在卷长上下文优化:Flash Attention(分块计算,不存完整矩阵)、Ring Attention(多卡分布式)、Sliding Window(局部窗口)等。
全流程回顾
把整个推理流程串一遍:
"请将你好翻译成英文" ↓ Tokenizer (BPE)[token1, token2, ..., token9] ↓ Embedding Matrix lookup[X1, X2, ..., X9] shape: (9, 4096) ↓ Transformer Layer 1~32(Prefill,全量计算)每层:LayerNorm → Attention(+残差) → LayerNorm → FFN(+残差) ↓ 最后一层输出 Z9 ↓ LM Head (= Embedding Matrix^T)logits: (128000,) ↓ softmax → 概率采样"Hello" ↓ Decode 阶段,逐 token 生成,利用 KV Cache...历史背景
在了解了整个架构之后,我们可以更好地理解不同流派的模型差异:
| 模型类型 | 注意力方向 | 适用场景 | 代表模型 |
|---|---|---|---|
| Encoder (BERT) | 双向 ↔️ | 完形填空、理解任务 | BERT, RoBERTa |
| Decoder (GPT) | 单向 → | 自回归、生成任务 | GPT, Claude, Llama |
| Encoder-Decoder | 编码双向,解码单向 | 翻译等 Seq2Seq 任务 | T5, 原版 Transformer |
2017 年 Google 发布的 Attention Is All You Need 论文最初提出的是 Encoder-Decoder 架构。论文标题就是宣言——只靠 Attention 就够了,干掉 RNN。
在此之前,RNN/LSTM 是序列建模的主流,但有致命缺陷:必须串行计算,长距离依赖难学。Transformer 用 Self-Attention 替代了循环结构,实现了完全并行计算。
| 时间 | 里程碑 |
|---|---|
| 2017.06 | Transformer 论文发布 |
| 2018.06 | GPT-1(OpenAI,Decoder-only) |
| 2018.10 | BERT(Google,Encoder-only) |
| 2020.05 | GPT-3(175B 参数) |
| 2022.11 | ChatGPT(RLHF 对齐) |
| 2023+ | GPT-4, Claude, Gemini, Llama… |