
记一次数据处理
一批这样的数据

要对其进行处理:
- 删除拼音字段和值

- 将其按省(province)分组

使用vim替换所有拼音字段
:%s/,\s"pinyin":..\w*"//以上是正确的替换方式, 并且进行了好多次错误的尝试:
s/"pinyin"[^,]*,/ # 错误
s/"pinyin"...[a-z]+"/ # 错误这些正则表达式有些可以在在线正则网站上测试通过, 可放到vim(sed)中却不能使用, 原因是:
On OSX, sed by default uses basic REs. You should use sed -E if you want to use modern REs, including the ”+” one-or-more operator.
in old, obsolete re
+is an ordinary character (as well as|,?)
使用node将去除pinyin字段的数据再组合封装
封装代码如下:
function trans() {
const newCities = [];
cities.forEach(c => {
const id = newCities.findIndex(nc => nc.province === c.province);
if (id === -1) {
newCities.push({
province: c.province,
cities: [{code: c.code, city: c.city}],
});
} else {
newCities[id].cities.push({
code: c.code,
city: c.city,
});
}
});
return newCities;
}其中使用console.log的形式再配合pipe将输出导入到after.js中的结果是这样的:
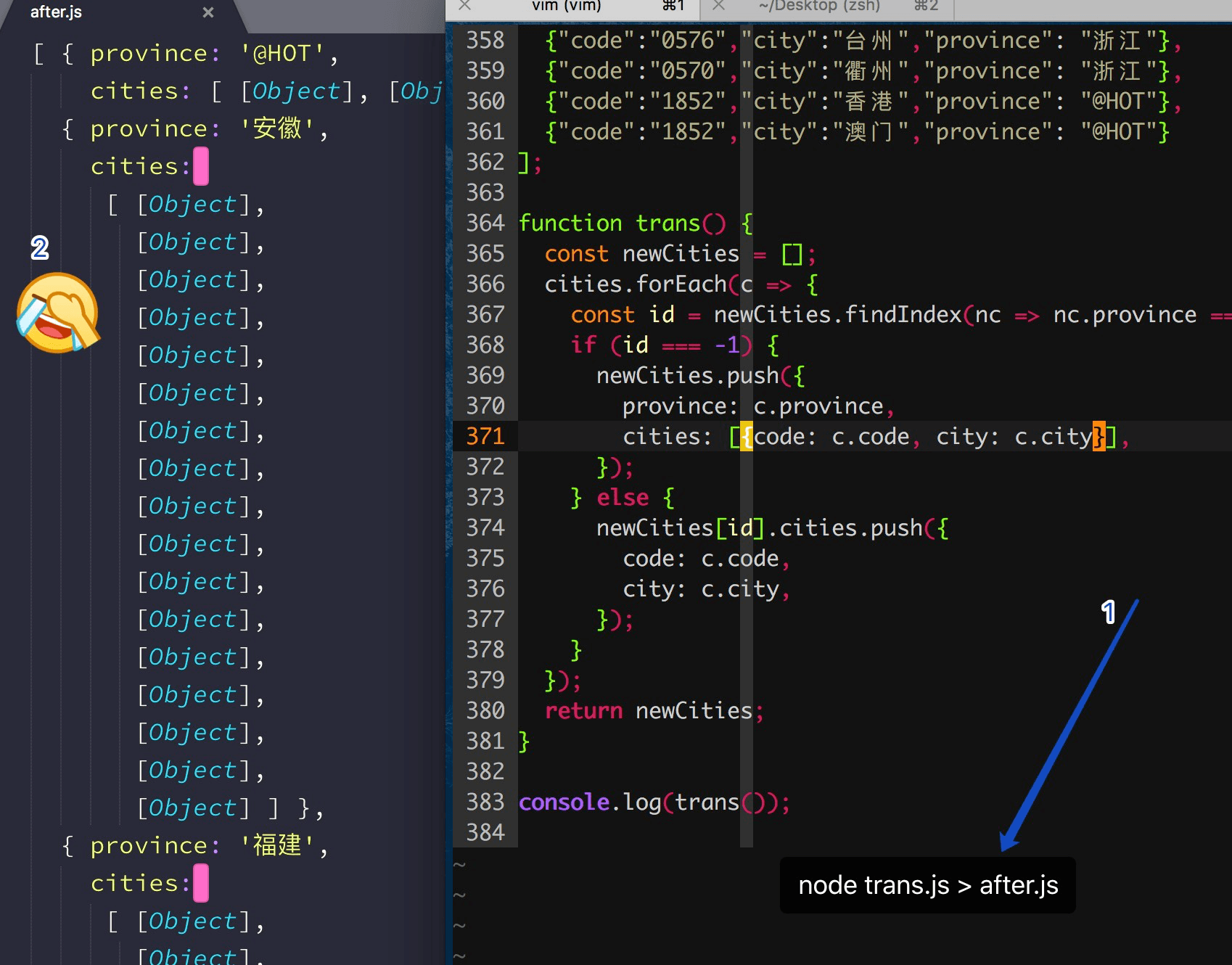
所以只好用fs导入到json中:
const fs = require('fs');
const after = trans();
fs.writeFile('./after.json', JSON.stringify(after) , 'utf-8');



